Introduction
Despite remarkable progress in text-to-image generation, state-of-the-art method fails to generate realistic mirror reflections. We put recent state-of-the-art models, Stable Diffusion 3.5 and FLUX to generate a scene with realistic and coherent reflections.

Prompt: A perfect plane mirror reflection of a mug which is placed in front of the mirror.

Prompt: A perfect plane mirror reflection of a stuffed toy bear which is placed in front of the mirror.
We observe that T2I methods fail on the challenging task of generating realistic and plausible mirror reflections. Either they get the orientation of the object wrong in the reflection or fail to create a photo-realistic scene with mirror placed in it.
Further, inpainting methods also fail in this task. Recent method to generate realistic and controllable mirror reflections, MirrorFusion also falls short on real-world and challenging scenes as apparent in the below figure.

Prompt: All the images were generated by prefixing the mirror text prompt: "A perfect plain mirror reflection
of " to the input object description.
We demonstrate that a generative method trained on the SynMirrorV2 dataset performs well in complex multi-object scenarios and effectively generalizes to real-world scenarios.
Dataset
We find that previous mirror datasets are not enough to train a generative model and are not tailored for the mirror reflection generation task. Further, previously proposed SynMirror lacks key augmentations such as object grounding, rotation, and multi-object scenarios, which restrict the model, which is trained on SynMirror, to generalize to real-world scenes.
We introduce SynMirrorV2, a dataset enhanced with key augmentations such as object grounding, rotation, and support for multiple objects within a scene. To create the dataset, we use 3D assets from Objaverse and Amazon Berkeley Objects (ABO).
We employ BlenderProc to render each 3D object along with its corresponding depth map, normal map, and segmentation mask. For each object, we generate three random views and apply augmentations, including varied object placement and orientation relative to the mirror within the scene.
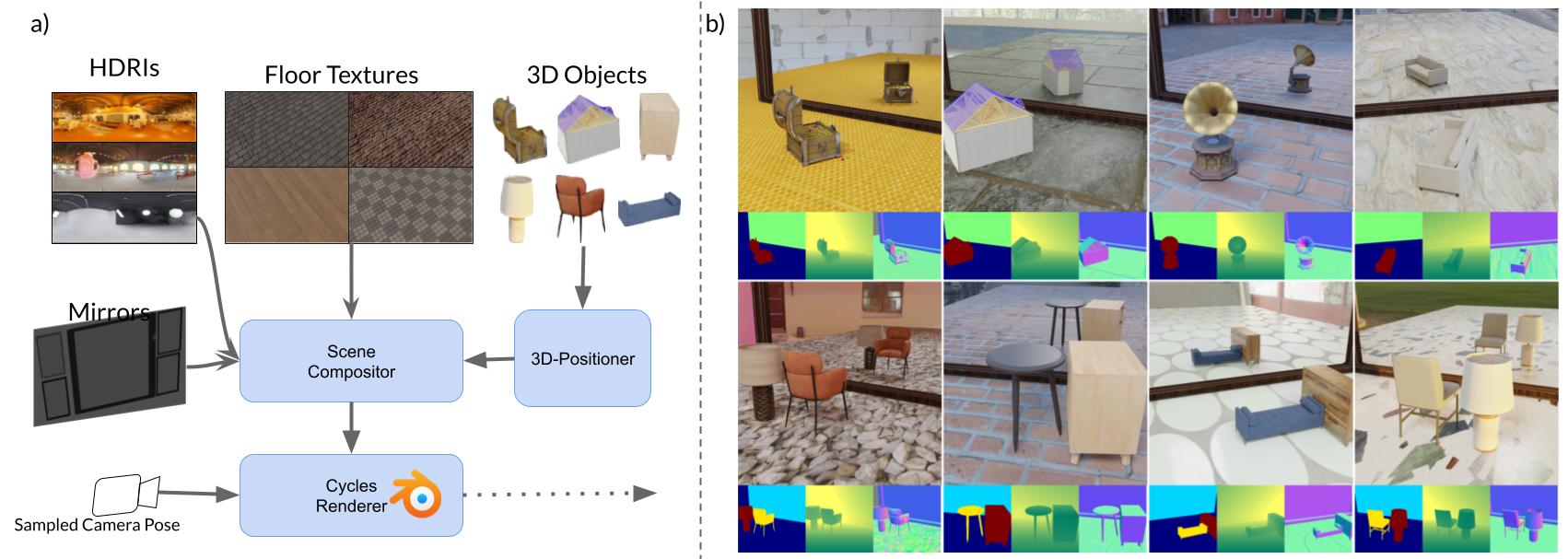
Our dataset generation pipeline introduces key augmentations such as random positioning, rotation, and grounding of objects within the scene using the 3D-Positioner. Additionally, we pair objects in semantically consistent combinations to simulate complex spatial relationships and occlusions, capturing realistic interactions for multi-object scenes.
| Dataset |
Type |
Size |
Attributes |
| MSD |
Real |
4018 |
RGB, Masks |
| Mirror-NeRF |
Real & Synthetic |
9 scenes |
RGB, Masks, Multi-View |
| DLSU-OMRS |
Real |
454 |
RGB, Mask |
| TROSD |
Real |
11060 |
RGB, Mask |
| PMD |
Real |
6461 |
RGB, Masks |
| RGBD-Mirror |
Real |
3049 |
RGB, Depth |
| Mirror3D |
Real |
7011 |
RGB, Masks, Depth |
| SynMirror |
Synthetic |
198204 |
Single Fixed Objects: RGB, Depth,Masks, Normals, Multi-View |
| SynMirrorV2 (Ours) |
Synthetic |
207610 |
Single + Multiple Objects: RGB, Depth,
Masks, Normals, Multi-View, Augmentations |
A comparison between SynMirrorV2 and other mirror datasets. SynMirrorV2 surpasses existing
mirror datasets in terms of attribute diversity and variability.
Qualitative Results

Comparison with MirrorFusion.
We compare our method with the baseline MirrorFusion on MirrorBenchV2. The baseline method shown struggles with pose variations, even in single-object scenes, and fails to produce accurate reflections for multiple objects. In contrast, our method handles variations in the object orientation effectively and generates geometrically accurate reflections, even in complex, multi-object scenarios.

Comparison on Real-World Dataset.
We show results for MirrorFusion, our method and our method fine-tuned on the MSD dataset. We observe that our method can generate reflections capturing the intricacies of complex scenes, such as a cluttered cable on the table and the presence of two mirrors in a 3D scene.
